OOP
Contents
OOP¶
Object oriented programming (OOP) is a design principle. It’s base is a class, a blueprint for a digital object:
we can store data (properties) in an object
we can perform actions on this data through built-in functions
we can create numerous instances of the same class, but all are independent
For example all strings belong to the class str. Each string is one independent instance of that class. It stores data (the text) and methods to process (and return) this data.
a = 'the quick brown fox'
b = 'jumps over the lazy dog'
print(type(a))
print(a)
print(a.title())
print(b.swapcase())
<class 'str'>
the quick brown fox
The Quick Brown Fox
JUMPS OVER THE LAZY DOG
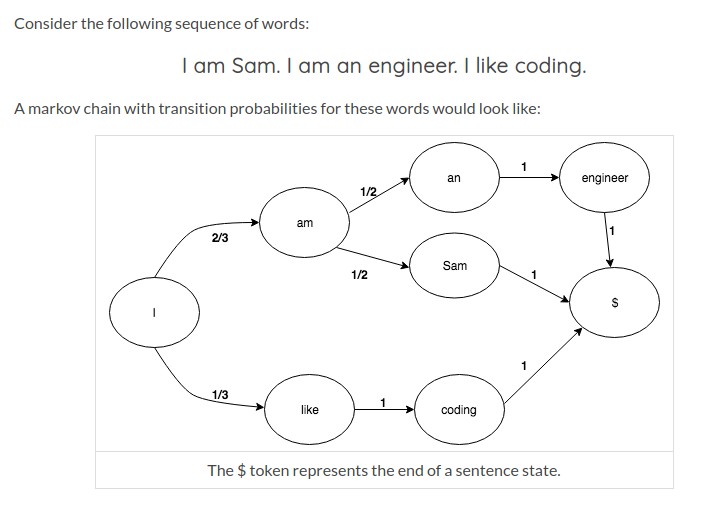
Markov Chain¶
Markov chains are a very simple but powerful method to predict the next value based on the previous value(s). The principle is not limited to text generation, but often used to generate text. It could be used for example to suggest next words on a mobile phone or a search engine.
Principle: Data (for e.g. text) is analyzed to create probability tables.
Source
In the following we’ll implement a simple markov chain, first without OOP, then with OOP to see the difference.
Without OOP¶
Tokenizer¶
# Text corpora for the probabilities:
txt = '''The quick brown fox jumps over the lazy dog. The lazy programmer jumps over the libre wolf.'''
# Split into tokens.
from nltk.tokenize import word_tokenize
txt = word_tokenize(txt)
print(txt[:15])
['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', 'The', 'lazy', 'programmer', 'jumps', 'over']
Dictionary¶
dic = {}
for i in range(len(txt)-1):
key = txt[i]
value = txt[i+1]
# Check if key exists:
if key in dic.keys():
# Append the value to the key
dic[key].append(value)
# Else add a new key + the value (as list)
else:
dic[key] = [value]
dic
{'The': ['quick', 'lazy'],
'quick': ['brown'],
'brown': ['fox'],
'fox': ['jumps'],
'jumps': ['over', 'over'],
'over': ['the', 'the'],
'the': ['lazy', 'libre'],
'lazy': ['dog', 'programmer'],
'dog': ['.'],
'.': ['The'],
'programmer': ['jumps'],
'libre': ['wolf'],
'wolf': ['.']}
Get possibilities¶
input_ = 'lazy'
possibilities = dic[input_]
print(possibilities)
['dog', 'programmer']
# Pick one possibility
import random
new_token = random.choice(dic[input_])
print(new_token)
programmer
Generate text¶
input_ = 'The'
new_txt = word_tokenize(input_)
punct = ['.', '?', '!']
while not new_txt[-1] in punct:
new_token = random.choice(dic[new_txt[-1]])
new_txt.append(new_token)
# Join list to string
new_txt = ' '.join(new_txt)
for p in punct:
new_txt = new_txt.replace(' '+p, p)
print(new_txt)
The lazy programmer jumps over the libre wolf.
With OOP¶
class Markov():
'''Generate a text with a simple one-word based markov chain.'''
def __init__(self, txt):
self.txt = txt
txt = '''The quick brown fox jumps over the lazy dog. The lazy programmer jumps over the libre wolf.'''
m = Markov(txt)
print(m.txt)
The quick brown fox jumps over the lazy dog. The lazy programmer jumps over the libre wolf.
Tokenizer¶
class Markov():
'''Generate a text with a simple one-word based markov chain.'''
def __init__(self, txt):
from nltk.tokenize import word_tokenize
self.txt = word_tokenize(txt)
txt = '''The quick brown fox jumps over the lazy dog. The lazy programmer jumps over the libre wolf.'''
m = Markov(txt)
print(m.txt)
['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', 'The', 'lazy', 'programmer', 'jumps', 'over', 'the', 'libre', 'wolf', '.']
Dictionary¶
class Markov():
'''Generate a text with a simple one-word based markov chain.'''
def __init__(self, txt):
from nltk.tokenize import word_tokenize
self.txt = word_tokenize(txt)
self.dic = self.create_dictionary()
def create_dictionary(self):
dic = {}
for i in range(len(self.txt)-1):
key = self.txt[i]
value = self.txt[i+1]
# Check if key exists
if key in dic.keys():
dic[key].append(value)
else:
dic[key] = [value]
return dic
txt = '''The quick brown fox jumps over the lazy dog. The lazy programmer jumps over the libre wolf.'''
m = Markov(txt)
print(m.txt)
print(m.dic)
['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', 'The', 'lazy', 'programmer', 'jumps', 'over', 'the', 'libre', 'wolf', '.']
{'The': ['quick', 'lazy'], 'quick': ['brown'], 'brown': ['fox'], 'fox': ['jumps'], 'jumps': ['over', 'over'], 'over': ['the', 'the'], 'the': ['lazy', 'libre'], 'lazy': ['dog', 'programmer'], 'dog': ['.'], '.': ['The'], 'programmer': ['jumps'], 'libre': ['wolf'], 'wolf': ['.']}
Generate text¶
class Markov():
'''Generate a text with a simple one-word based markov chain.'''
def __init__(self, txt):
from nltk.tokenize import word_tokenize
self.txt = word_tokenize(txt)
self.dic = self.create_dictionary()
def create_dictionary(self):
dic = {}
for i in range(len(self.txt)-1):
key = self.txt[i]
value = self.txt[i+1]
# Check if key exists
if key in dic.keys():
dic[key].append(value)
else:
dic[key] = [value]
return dic
def generate_sentence(self, input_):
from nltk.tokenize import word_tokenize
import random
new_txt = word_tokenize(input_)
punct = ['.', '?', '!']
while not new_txt[-1] in punct:
new_token = random.choice(self.dic[new_txt[-1]])
new_txt.append(new_token)
# Join list to string
new_txt = ' '.join(new_txt)
for p in punct:
new_txt = new_txt.replace(' '+p, p)
return new_txt
txt = '''The quick brown fox jumps over the lazy dog. The lazy programmer jumps over the libre wolf.'''
m = Markov(txt)
m.generate_sentence('The')
'The lazy dog.'
Inheritance¶
The class below inherits everything from the class Markov() and extends it with a function to generate more than one sentence. The code is a little bit ugly, so it’s good to hide it inside a class.
class Markovs_Child(Markov):
def generate_sentences(self, n, input_):
from nltk.tokenize import word_tokenize
import random
sentences = input_
for i in range(n):
input_ = word_tokenize(sentences)[-1]
# generate_sentence will stop on a punct [., !, ?]
# Therefore a new input will be picked manually here
if input_ in ['.', '!', '?']:
input_ = random.choice(self.dic[input_])
new_sentence = self.generate_sentence(input_)
if i == 0:
sentences = new_sentence
else:
sentences += ' ' + new_sentence
return sentences
mc = Markovs_Child(txt)
print(mc.generate_sentence('The'))
print(mc.generate_sentences(4, 'The'))
The lazy programmer jumps over the lazy programmer jumps over the lazy dog.
The quick brown fox jumps over the lazy dog. The lazy programmer jumps over the libre wolf. The lazy programmer jumps over the lazy dog. The lazy dog.
When are classes useful?¶
If you need/ want to store data and methods in the same object
If you need multiple instances of the same object
If you want to want to write more sophisticated modular/ reusable code (for example to share it as a library)